
Цель урока: Начать наш большой финальный проект второго блока. Мы спроектируем структуру нашего будущего скрипта аудита и сразу же реализуем первые функции для сбора базовой информации о системе. Это позволит нам не только заложить правильную архитектуру, но и получить первый работающий прототип нашего инструмента уже сегодня.
Часть 1: Постановка задачи. Что мы хотим получить?
Наша цель - создать скрипт system_audit.sh, который при запуске будет собирать ключевые параметры сервера и выводить их в виде четкого и понятного отчета.
Определим структуру отчета:
-
Общая информация о системе: Имя хоста, дистрибутив, версия ядра, время работы.
-
Информация о CPU: Модель, количество ядер, текущая загрузка.
-
Информация о RAM: Общий объем, использовано, свободно.
-
Информация о дисках: Список файловых систем, их размер, использование.
-
Информация о сети: IP-адреса, открытые порты.
Часть 2: Практика. Создаем "скелет" и "оживляем" его
Мы создадим файл, заложим в него правильную структуру с функциями-заглушками, а затем сразу наполним кодом первые две функции, чтобы увидеть результат.
Шаг 1: Создание файла и базовой структуры
Перейдем в наш каталог со скриптами и создадим новый файл.
cd ~/scripts
nano system_audit.sh
Вставим в `nano` "скелет" нашего скрипта.
#!/bin/bash
# ==============================================================================
#
# FILE: system_audit.sh
#
# USAGE: ./system_audit.sh
#
# DESCRIPTION: Скрипт для проведения базового аудита системы Linux.
#
# ==============================================================================
# --- ОБЪЯВЛЕНИЕ ФУНКЦИЙ ---
# Функция для вывода красивого заголовка раздела
# Принимает один аргумент - текст заголовка
print_header() {
printf "\n%s\n" "--------------------------------------------------------------------"
printf " %s\n" "$1"
printf "%s\n" "--------------------------------------------------------------------"
}
# Функция для сбора общей информации о системе
get_system_info() {
print_header "1. Общая информация о системе"
# Здесь мы напишем код прямо сейчас
}
# Функция для сбора информации о CPU
get_cpu_info() {
print_header "2. Информация о CPU"
# И здесь тоже
}
# Функция для сбора информации о RAM (пока заглушка)
get_memory_info() {
print_header "3. Информация о RAM"
echo "Эта функция будет реализована в следующем уроке."
}
# Функция для сбора информации о дисках (пока заглушка)
get_disk_info() {
print_header "4. Информация о дисковом пространстве"
echo "Эта функция будет реализована в следующем уроке."
}
# Функция для сбора информации о сети (пока заглушка)
get_network_info() {
print_header "5. Информация о сети"
echo "Эта функция будет реализована в следующем уроке."
}
# --- ОСНОВНОЙ БЛОК (MAIN) ---
main() {
get_system_info
get_cpu_info
get_memory_info
get_disk_info
get_network_info
}
# Запускаем нашу главную функцию
mainШаг 2: Реализация функции get_system_info
Теперь вернемся в nano к функции get_system_info и заменим комментарий на реальные команды. Мы будем использовать printf для красивого выравнивания.
Что такое printf?
Это команда для форматированного вывода. printf "формат" "аргумент1" "аргумент2"
-
%-20s: s означает "строка". 20 - выделить 20 символов под эту строку. - - выровнять по левому краю.
-
%s: Просто вставить строку.
-
\n: Перевод на новую строку.
Код для get_system_info:
get_system_info() {
print_header "1. Общая информация о системе"
printf "%-20s: %s\n" "Имя хоста" "$(hostname)"
printf "%-20s: %s\n" "Дистрибутив" "$(lsb_release -d | cut -f2-)"
printf "%-20s: %s\n" "Версия ядра" "$(uname -r)"
printf "%-20s: %s\n" "Время работы" "$(uptime -p)"
}Разбор команд:
-
hostname: Возвращает имя хоста.
-
lsb_release -d | cut -f2-: lsb_release -d выводит строку "Description: Ubuntu 22.04.3 LTS". Чтобы убрать "Description:", мы используем cut с разделителем-табуляцией (-f2-) и забираем второе и последующие поля.
-
uname -r: Показывает версию ядра Linux.
-
uptime -p: Показывает время работы системы в "красивом" формате (p - pretty).
Шаг 3: Реализация функции get_cpu_info
Аналогично заполняем вторую функцию.
Код для get_cpu_info:
get_cpu_info() {
print_header "2. Информация о CPU"
printf "%-20s: %s\n" "Модель" "$(cat /proc/cpuinfo | grep 'model name' | uniq | cut -d: -f2- | sed 's/^[ \t]*//')"
printf "%-20s: %s\n" "Количество ядер" "$(nproc)"
printf "%-20s: %s\n" "Текущая загрузка" "$(top -bn1 | grep '%Cpu(s)' | awk '{print $2 + $4}')%"
}Разбор команд:
-
cat /proc/cpuinfo | ...: Вся информация о процессоре лежит в виртуальном файле /proc/cpuinfo. Мы читаем его, находим (grep) строку с названием модели, убираем дубликаты (uniq), вырезаем (cut) нужную часть и убираем лишние пробелы в начале (sed).
-
nproc: Простая утилита, которая выводит количество доступных процессорных ядер.
-
top -bn1 | ...: Это хитрый способ получить среднюю загрузку CPU. top -bn1 запускает top в "пакетном" режиме (-b), делает один снимок (-n1) и завершается. Затем мы находим строку %Cpu(s) и с помощью awk складываем процент пользовательского времени ($2) и системного ($4).
Шаг 4: Сохранение, права и запуск
-
Убедитесь, что вы внесли изменения в обе функции.
-
В nano сохраните файл (Ctrl+O, Enter) и выйдите (Ctrl+X).
-
Сделайте скрипт исполняемым:
chmod +x system_audit.sh. -
Запустите его:
./system_audit.sh.
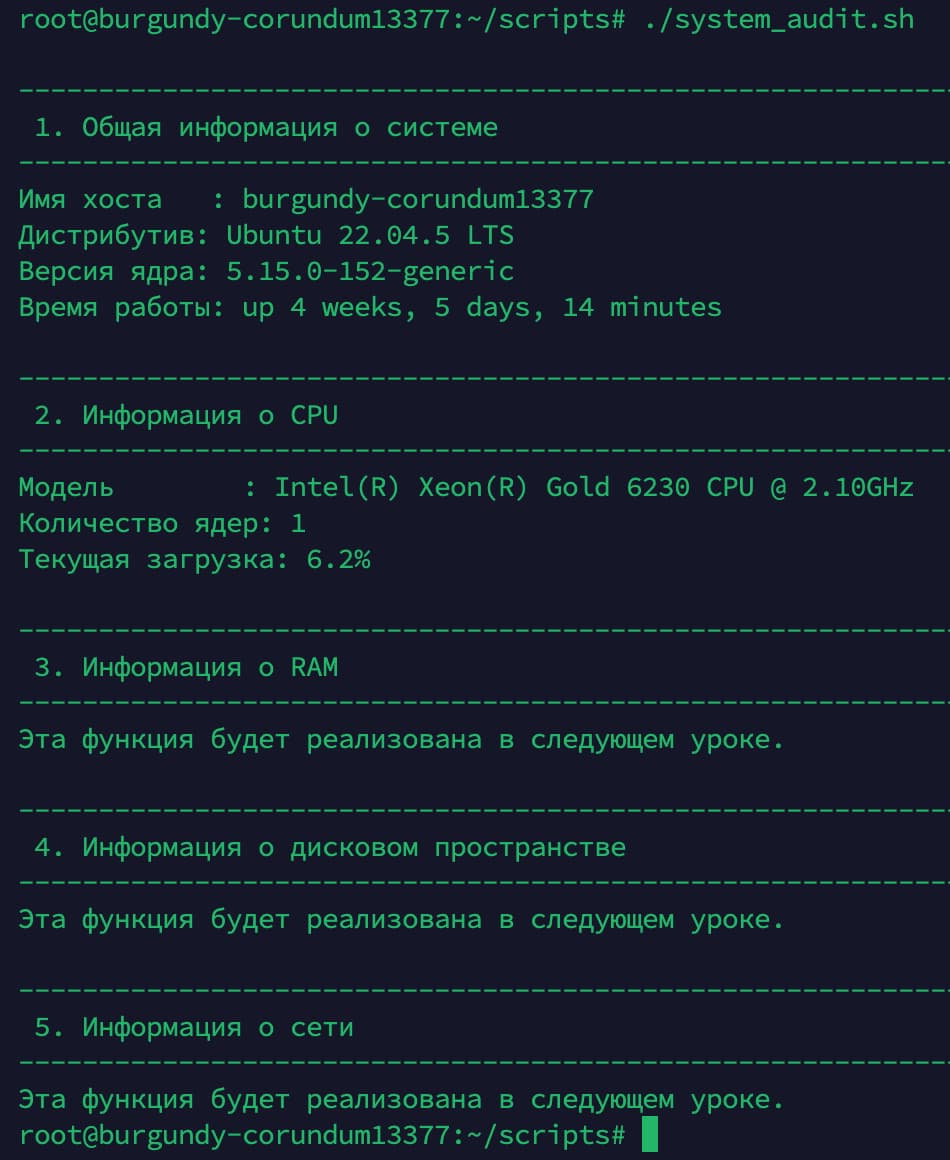
Ожидаемый результат:
Теперь ваш скрипт выведет не просто заголовки, а два полноценных, заполненных данными блока, за которыми будут следовать "заглушки" для будущих разделов. Вы получили первый рабочий прототип!
Часть 4: Заключение и план на следующие уроки
Сегодня мы проделали работу архитектора и строителя одновременно. Мы не только спроектировали наш инструмент, но и сразу же реализовали его первую, работающую версию. Мы заложили прочный каркас из функций и наполнили его реальными данными, получив мгновенный и полезный результат. Это показывает, как мощные однострочные команды, которые мы изучали ранее, становятся строительными блоками для создания сложных и полезных скриптов.
Наш план на следующие уроки (32-35):
-
Урок 32: Мы "оживим" функции get_memory_info и get_disk_info, используя free, df и другие знакомые нам команды.
-
Урок 33: Мы напишем код для функции get_network_info, добавив туда поиск открытых портов.
-
Урок 34-35: Мы проведем финальную сборку, "причешем" форматирование, добавим обработку ошибок и, возможно, параметры командной строки, чтобы завершить наш проект.
Перейти к просмотру - УРОК №32.
![]() Промо-код: PROMO15 - скидка 15%!
Промо-код: PROMO15 - скидка 15%! ![]()
Введите при оформлении первого заказа на сайте: Hosting-VDS.com

